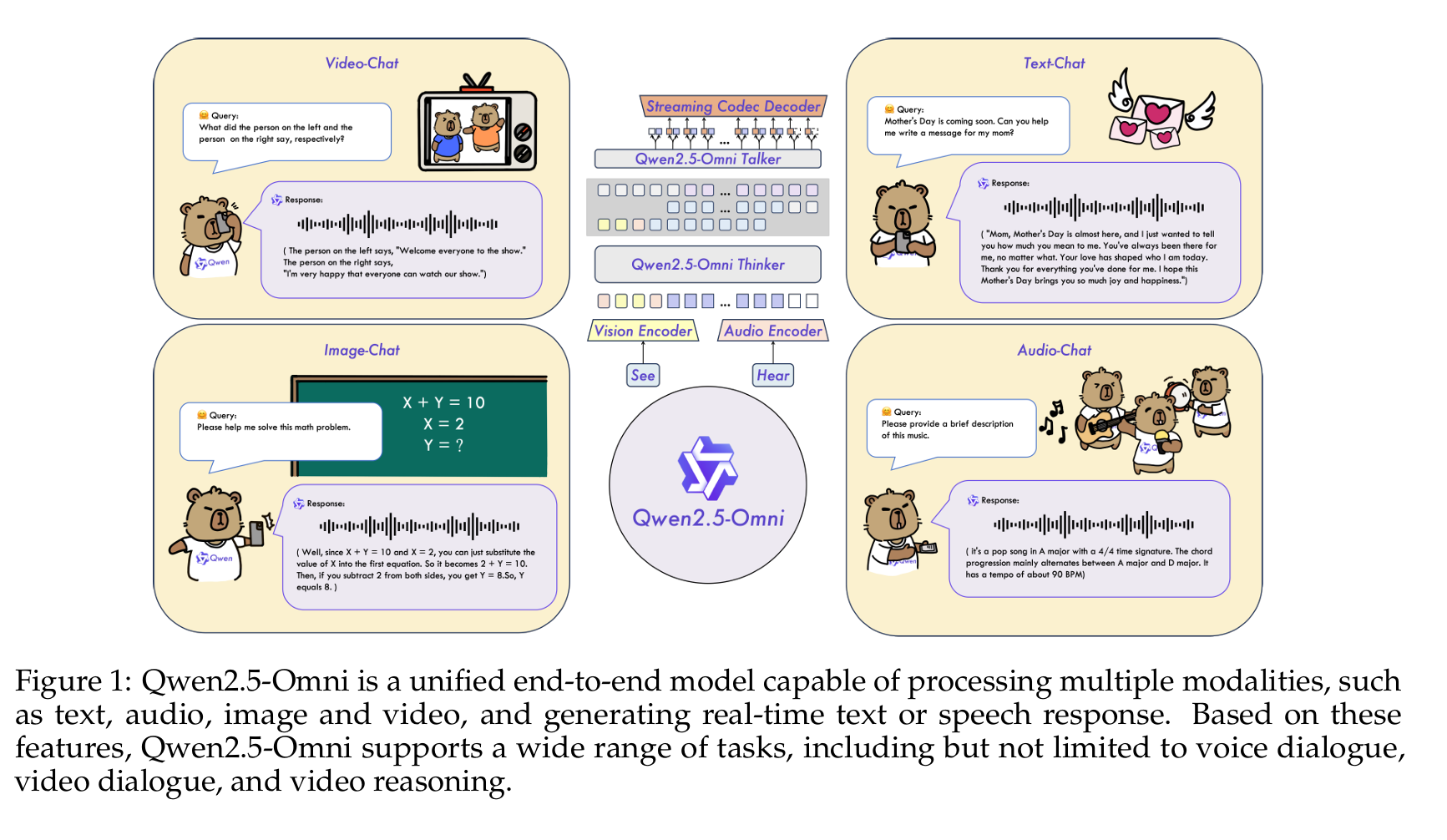
Artificial intelligence has taken a significant leap forward with the introduction of Qwen2.5-Omni, a unified end-to-end multimodal model developed by the Qwen Team. This cutting-edge AI system is designed to perceive diverse modalities including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. This article explores the architecture, capabilities, and performance of this revolutionary model that represents a major advancement toward more human-like AI interaction.
The Challenge of Unified Multimodal Intelligence
In recent years, the AI landscape has been transformed by Large Language Models (LLMs) trained on vast amounts of textual data. These models have demonstrated remarkable problem-solving abilities and rapid learning capabilities. Additionally, specialized models like Language-Audio-Language Models (LALMs) and Language-Visual-Language Models (LVLMs) have extended these capabilities to include auditory and visual understanding in an end-to-end manner.
However, creating a truly unified model that can efficiently process multiple modalities simultaneously while providing natural responses has presented significant challenges. These include:
- Implementing a systematic method for joint training of various modalities
- Synchronizing temporal aspects of audio and visual signals, particularly in video content
- Managing potential interference among outputs from different modalities
- Developing architectural designs that enable real-time understanding and efficient streaming
Qwen2.5-Omni tackles these challenges with innovative architectural solutions and training methodologies.
The Thinker-Talker Architecture
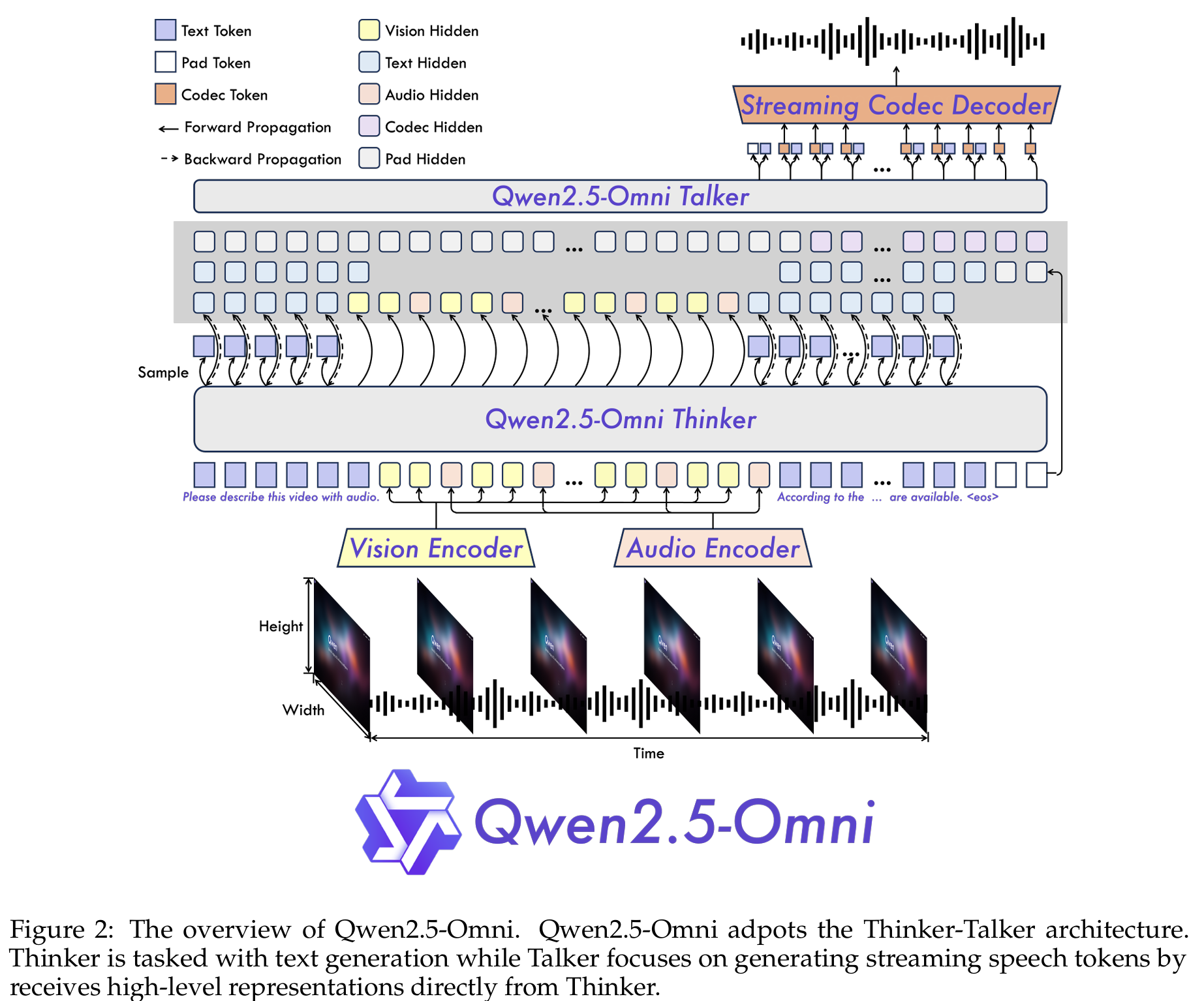
At the core of Qwen2.5-Omni is the novel Thinker-Talker architecture, which divides responsibilities in a way reminiscent of human cognitive processes. This design enables the model to process multimodal information in real-time and concurrently generate both text and speech1.
Thinker Component
The Thinker functions like a brain, responsible for:
- Processing and understanding inputs from text, audio, and video modalities
- Generating high-level representations and corresponding text
- Operating as a Transformer decoder with accompanying encoders for audio and image information extraction
The Thinker is essentially responsible for the cognitive aspects of understanding and generating content.
Talker Component
The Talker operates like a human mouth, designed to:
- Take high-level representations and text produced by the Thinker in a streaming manner
- Output discrete tokens of speech fluidly
- Function as a dual-track autoregressive Transformer Decoder
During both training and inference, the Talker directly receives high-dimensional representations from the Thinker and shares all context information. This allows the entire architecture to operate as a cohesive single model, enabling true end-to-end training and inference.
Multimodal Perception Capabilities
Qwen2.5-Omni processes various input modalities through specialized components and innovative techniques that ensure efficient alignment and integration.
Text Processing
For text tokenization, the model uses Qwen's tokenizer which applies byte-level byte-pair encoding with a vocabulary comprising 151,643 regular tokens.
Audio Processing
When handling audio input:
- Audio is resampled to a frequency of 16 kHz
- Raw waveforms are transformed into 128-channel mel-spectrograms with a window size of 25 ms and a hop size of 10 ms
- The audio encoder from Qwen2-Audio is adopted, allowing each frame to correspond to approximately 40 ms of the original audio signal
Image and Video Processing
For visual information:
- The model employs the vision encoder from Qwen2.5-VL, based on the Vision Transformer (ViT) model with approximately 675 million parameters
- This encoder is trained on both image and video data to ensure proficiency in both types of visual content
- Each image is treated as two identical frames for consistency
- Videos are sampled using a dynamic frame rate to preserve information while adapting to the audio sampling rate1
TMRoPE: A Novel Approach to Multimodal Synchronization
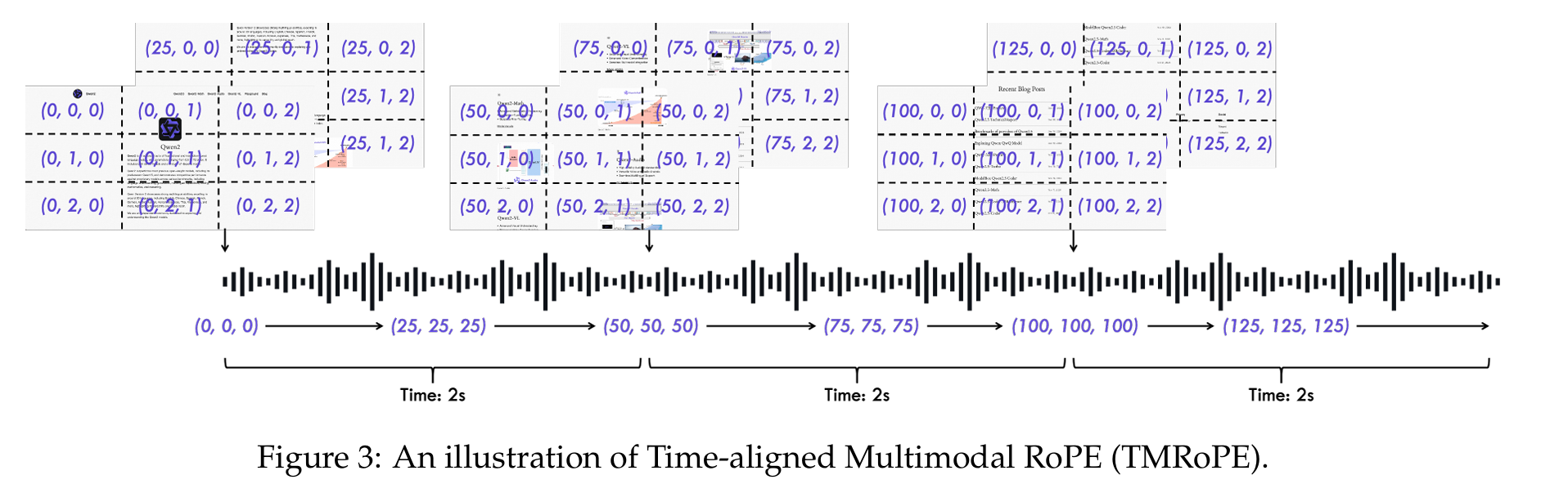
One of the most significant innovations in Qwen2.5-Omni is the Time-aligned Multimodal RoPE (TMRoPE), which addresses the challenge of synchronizing different modalities, particularly audio and video.
TMRoPE encodes 3-D positional information of multimodal inputs by deconstructing the original rotary embedding into three components:
- Temporal position
- Height position
- Width position
For different modalities, TMRoPE works as follows:
- Text inputs: Identical position IDs are used for all three components, making it functionally equivalent to 1D-RoPE
- Audio inputs: Identical position IDs are used with absolute temporal position encoding, where one temporal ID corresponds to 40 ms
- Images: Temporal IDs remain constant while distinct IDs are assigned to height and width components based on the token's position
- Video with audio: Audio is encoded with identical position IDs for every 40 ms frame, while video frames receive incremental temporal IDs with dynamic adjustment to ensure one temporal ID corresponds to 40 ms
This system enhances positional information modeling and maximizes the integration of various modalities, enabling the model to simultaneously understand and analyze information from multiple sources.
Streaming Design and Efficiency
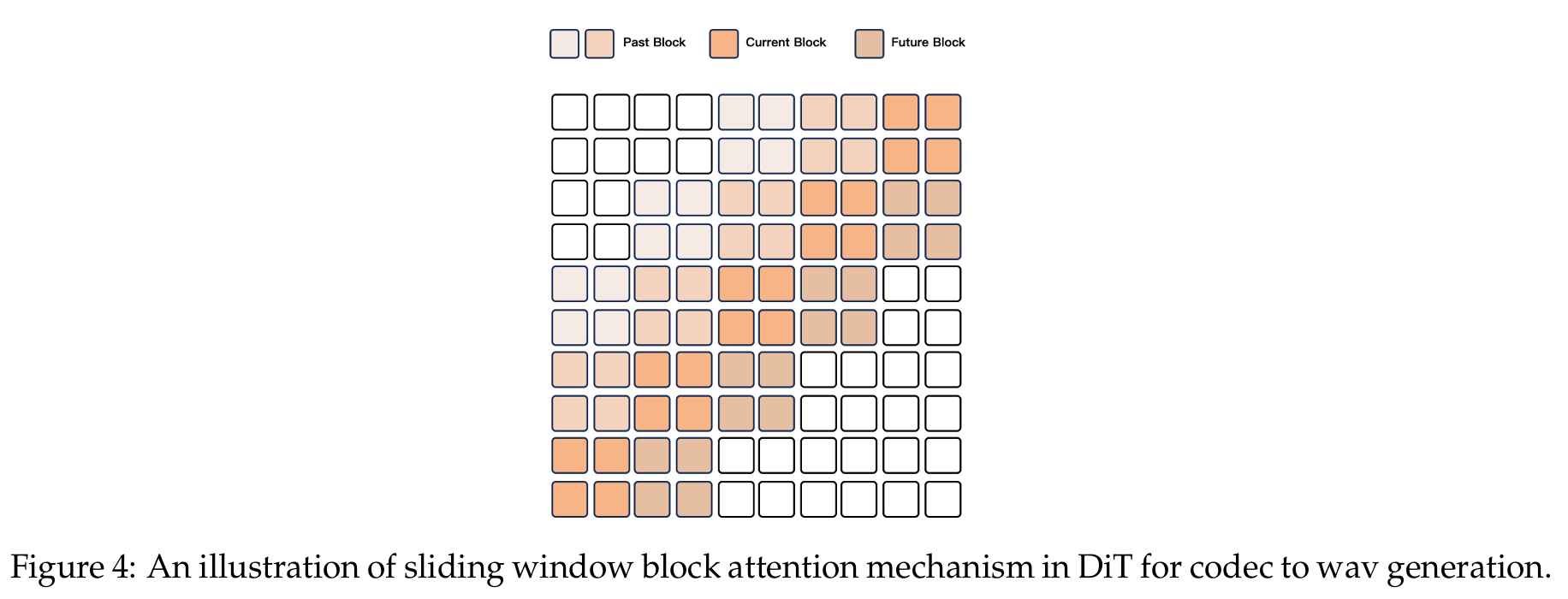
A critical aspect of Qwen2.5-Omni is its ability to process and generate content in a streaming manner, which requires minimizing initial latency while maintaining high-quality outputs.
Prefilling Support
To enable efficient streaming, the model implements:
- Block-wise attention along the temporal dimension in audio and visual encoders
- Processing of audio in blocks of 2 seconds each
- Flash attention for efficient training and inference in the vision encoder
- MLP layers that merge adjacent tokens to handle images of different resolutions1
Streaming Speech Generation
For streaming audio generation, the model employs:
- A sliding window block attention mechanism that restricts the current token's access to limited context
- A Flow-Matching DiT model that transforms input code into a mel-spectrogram
- A modified BigVGAN to reconstruct the generated mel-spectrogram back into waveform
- A chunk-by-chunk generation approach with a limited receptive field of 4 blocks (including a lookback of 2 blocks and a lookahead of 1 block)
This design significantly reduces the initial packet delay while maintaining high-quality speech output.
Training Methodology
Qwen2.5-Omni underwent a sophisticated three-stage training process to develop its comprehensive multimodal capabilities.
Stage 1: Specialized Encoder Training
In the first stage:
- The LLM parameters were locked
- Training focused exclusively on the vision encoder and audio encoder
- A vast corpus of audio-text and image-text pairs was used to enhance semantic understanding within the LLM
- The LLM component was initialized using parameters from Qwen 2.5
- The vision encoder matched Qwen2.5-VL, and the audio encoder was initialized with Whisper-large-v3
Stage 2: Comprehensive Multimodal Training
The second stage involved:
- Unfreezing all parameters
- Training with a wider range of multimodal data
- Incorporating an additional 800 billion tokens of image and video related data
- Adding 300 billion tokens of audio related data and 100 billion tokens of video with audio related data
- Maximum token length was limited to 8192 tokens for efficiency
Stage 3: Long-Sequence Training
In the final stage:
- Long audio and video data were incorporated
- Original text, audio, image, and video data were extended to 32,768 tokens
- This significantly improved the model's ability to handle long sequence data
Talker Training
The Talker component underwent an additional three-stage training process:
- Context Continuation - Learning to establish a monotonic mapping from semantic representation to speech
- Direct Preference Optimization (DPO) - Enhancing stability of speech generation using reinforcement learning
- Multi-speaker Instruction Fine-tuning - Improving naturalness and controllability of speech responses
Performance Evaluation
Qwen2.5-Omni has been rigorously evaluated across multiple domains and tasks, demonstrating exceptional capabilities in understanding and generating content across modalities.
Text Understanding and Generation
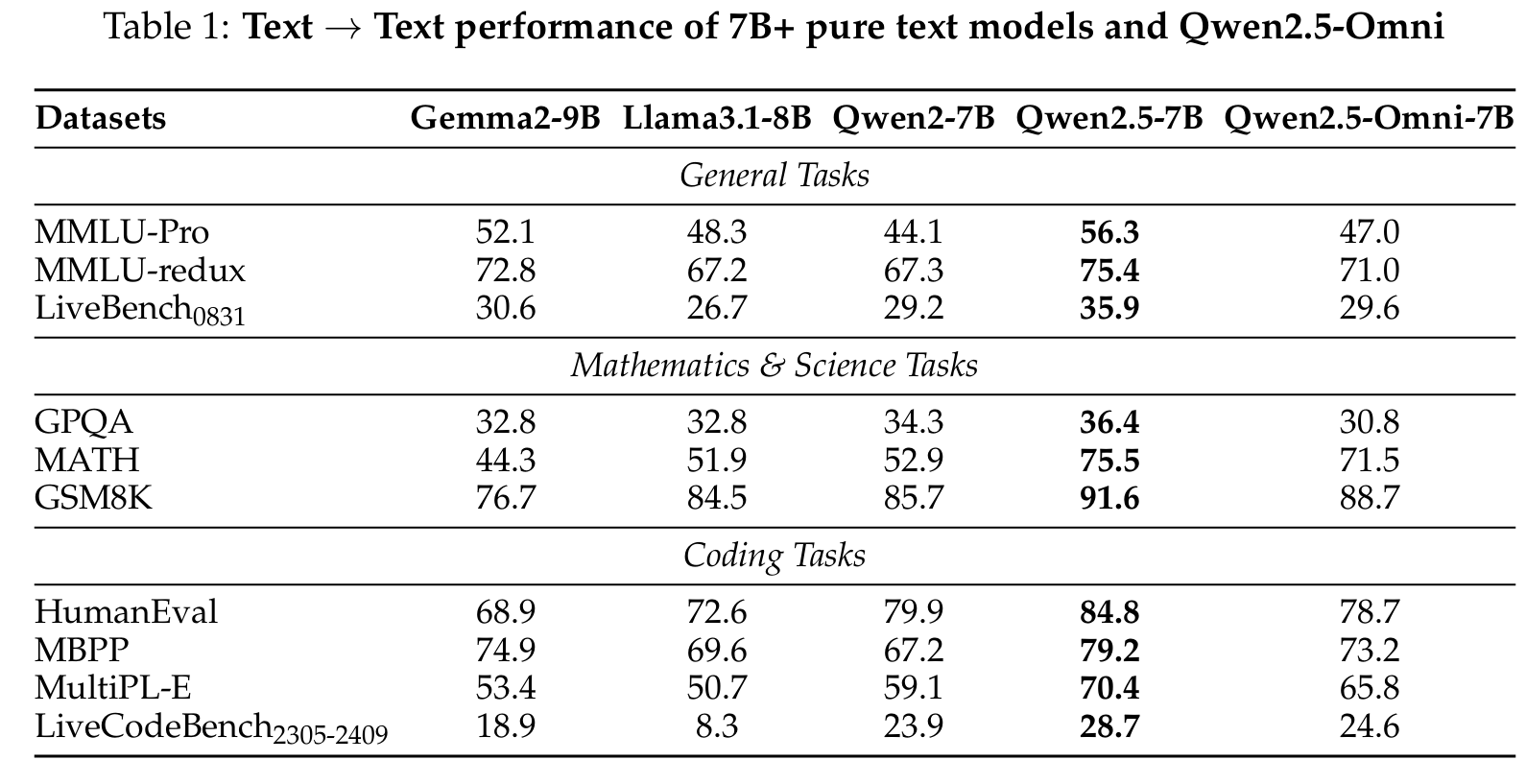
When evaluated on text-to-text tasks, Qwen2.5-Omni demonstrates performance between Qwen2-7B and Qwen2.5-7B on most benchmarks, outperforming Qwen2-7B on MMLU-Pro, MMLU-redux, MATH, GSM8K, MBPP, MultiPL-E, and LiveCodeBench.
Audio Processing Capabilities
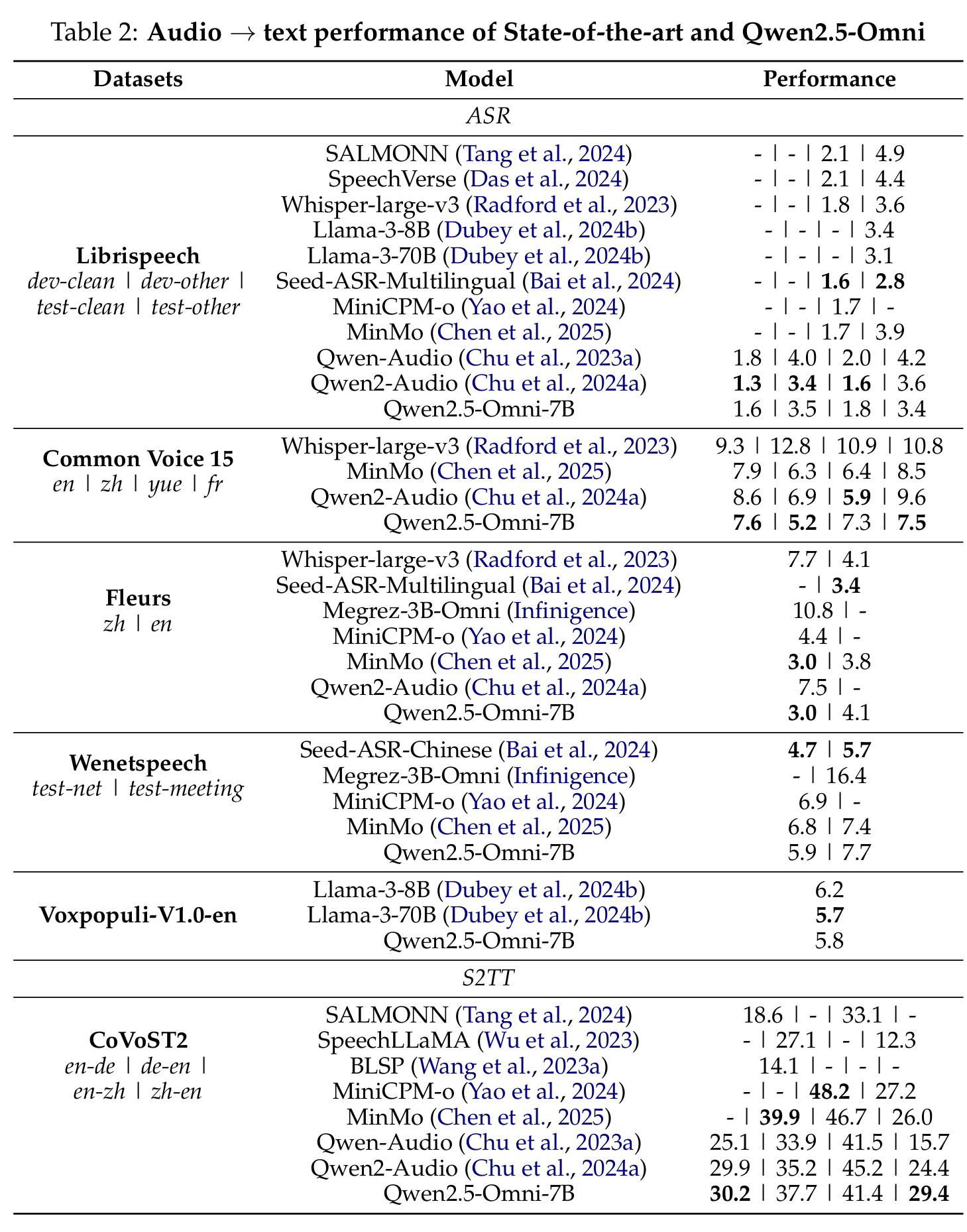
In audio understanding tasks, Qwen2.5-Omni outperforms or matches state-of-the-art models on:
- Automatic Speech Recognition (ASR) tasks, achieving superior performance on Fleurs_zh, CommonVoice_en, CommonVoice_zh, and other datasets
- Speech-to-Text Translation (S2TT)
- Speech Entity Recognition (SER)
- Vocal Sound classification (VSC)
- Music understanding
For voice interactions, the model achieves an impressive average score of 74.12 on VoiceBench, surpassing other audio language models and omni models of similar size.
Visual Understanding
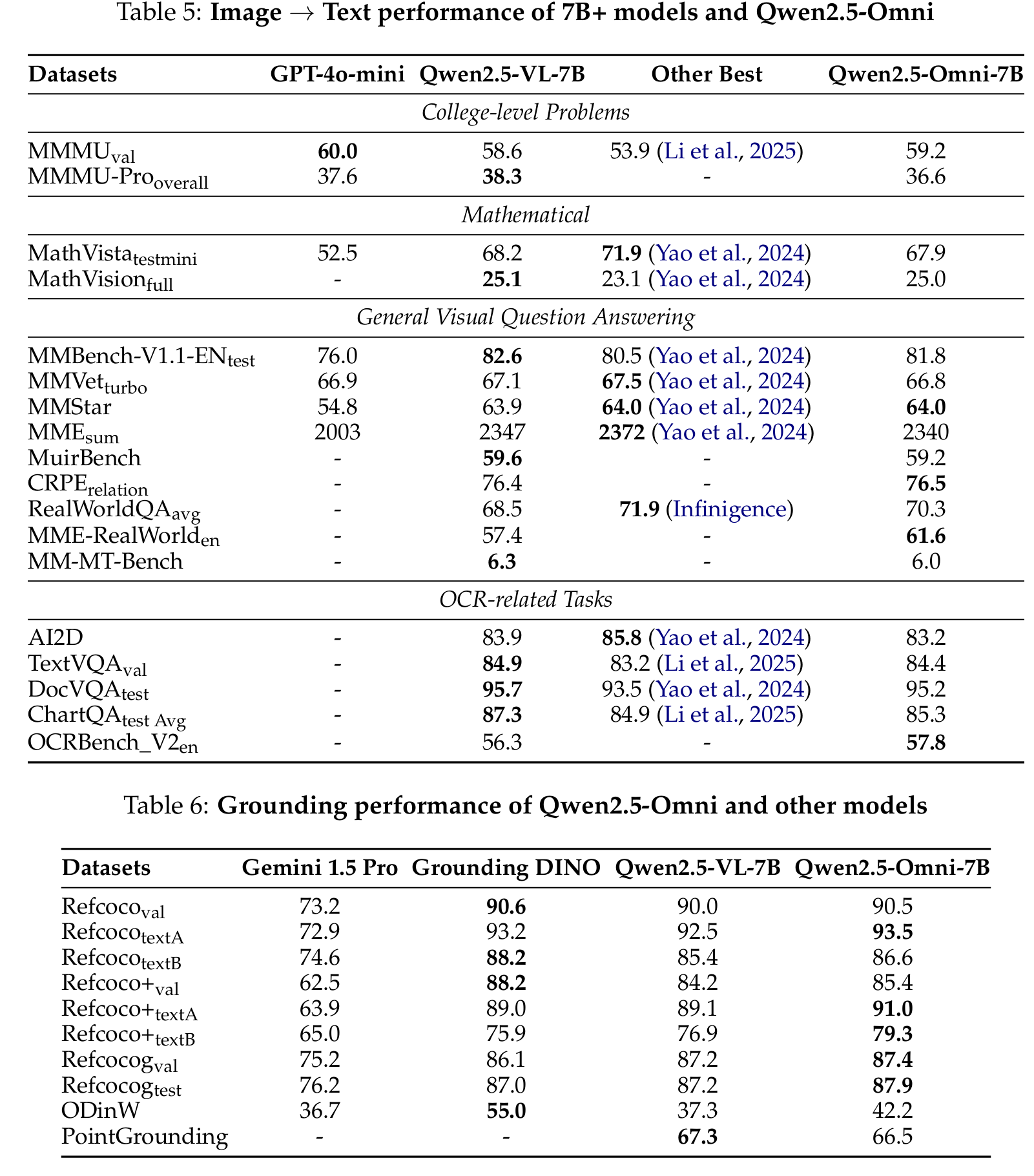
Qwen2.5-Omni demonstrates comparable performance to Qwen2.5-VL-7B on image understanding tasks, and outperforms other open-sourced omni models on benchmarks including:
- MMMU (college-level problems)
- MathVision (mathematical visual reasoning)
- MMBench-V1.1-EN (general visual question answering)
- TextVQA and DocVQA (OCR-related tasks)
Video Understanding
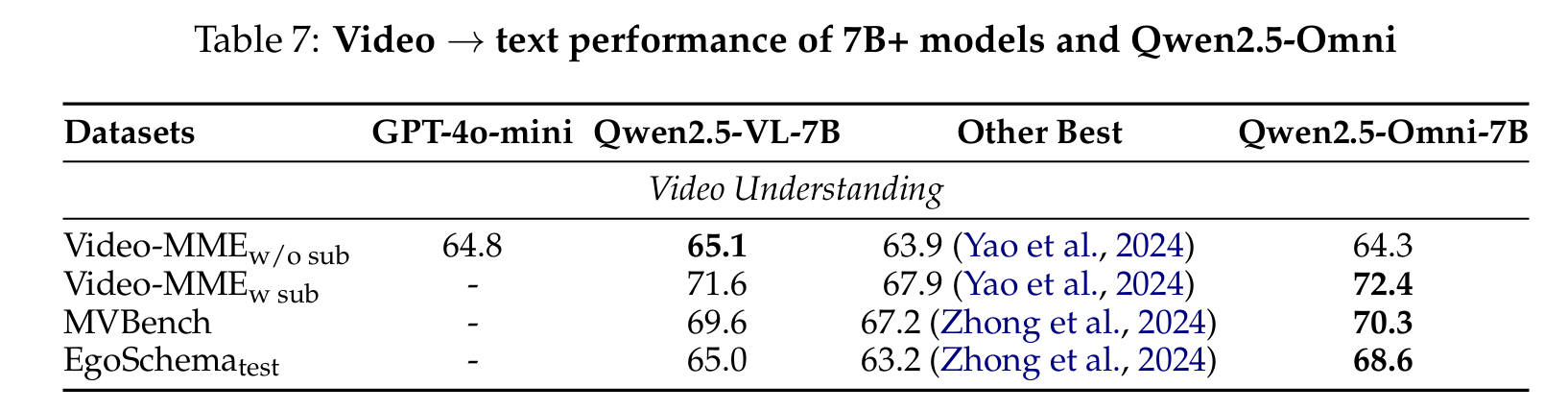
The model outperforms all other state-of-the-art open-sourced omni models and GPT-4o-Mini on video understanding benchmarks, achieving better or competitive results compared to Qwen2.5-VL-7B on:
- Video-MME
- MVBench
- EgoSchema
Multimodal Integration
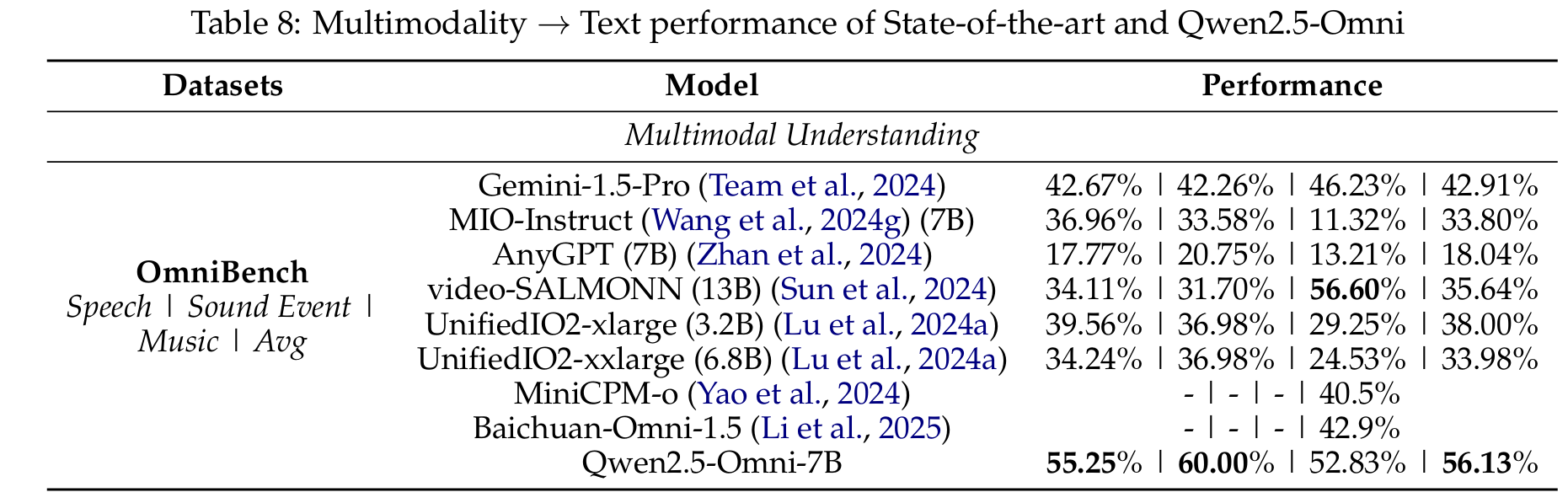
On OmniBench, which tests the ability to understand mixed-modality prompts (image, audio, and text), Qwen2.5-Omni achieves state-of-the-art performance, surpassing other omni models by a significant margin.
Speech Generation
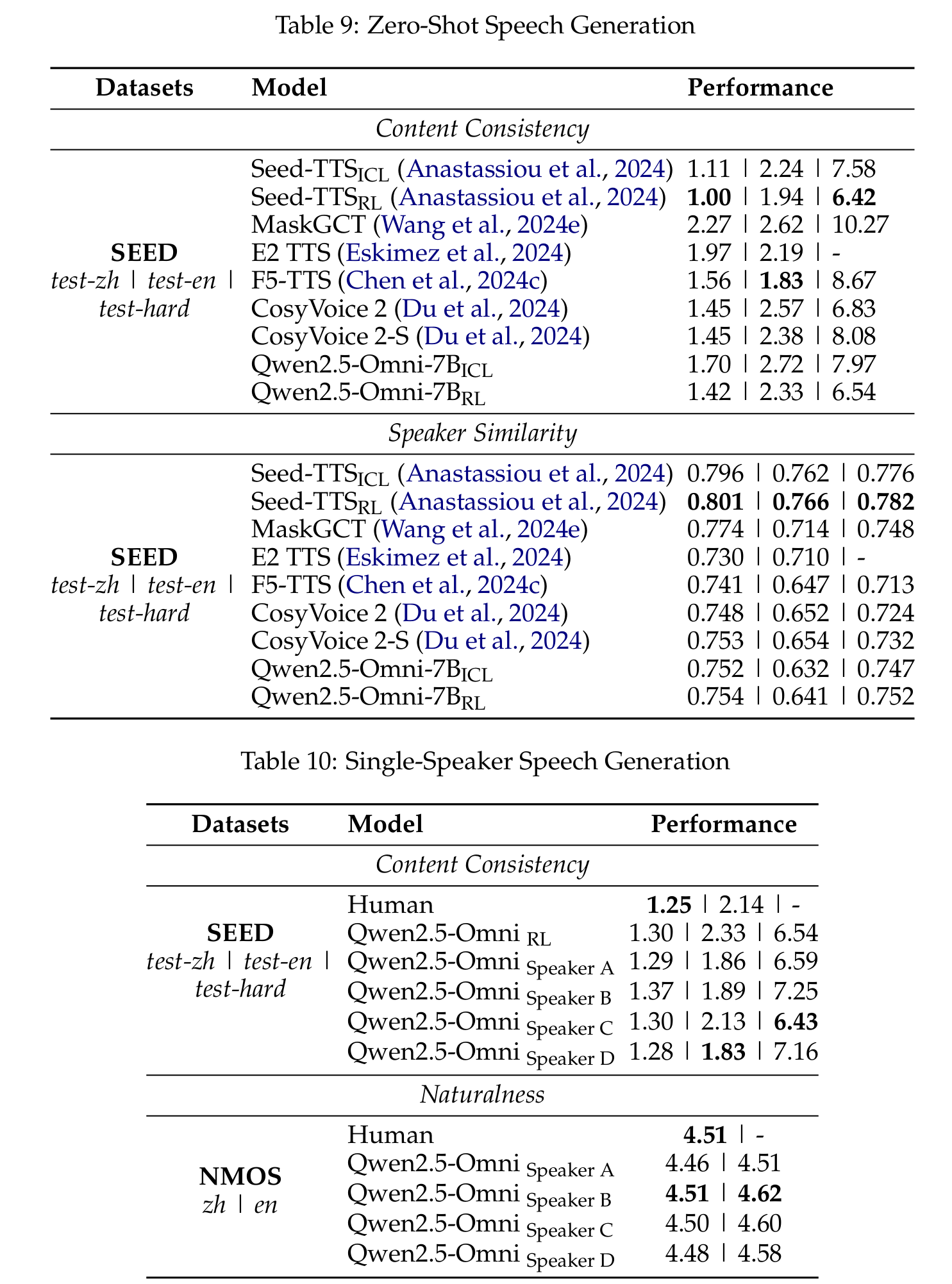
Qwen2.5-Omni demonstrates highly competitive performance in speech generation, with:
- Content consistency (WER) of 1.42%, 2.33%, and 6.54% on SEED test-zh, test-en, and test-hard sets respectively
- Strong speaker similarity scores
- Naturalness ratings approaching human-level quality after speaker fine-tuning
Implications and Future Directions
Qwen2.5-Omni represents a significant advancement in multimodal AI capabilities. Its ability to simultaneously process multiple modalities and generate both text and speech in a streaming manner opens new possibilities for more natural human-AI interaction.
The model excels in complex audio-visual interactions and emotional context in speech dialogues, addressing critical issues that have often been overlooked in previous academic studies, such as video OCR and audio-video collaborative understanding.
Future directions for development include:
- Creating a more robust and faster model
- Expanding output capabilities across additional modalities like images, videos, and music
- Further improving the synchronization between modalities
- Enhancing real-time processing and response generation
Conclusion
Qwen2.5-Omni represents a milestone in the development of artificial general intelligence (AGI). By unifying perception across modalities and enabling concurrent generation of text and speech, it bridges the gap between specialized AI systems and the more integrated intelligence that characterizes human cognition.
The model's innovative architecture, particularly the Thinker-Talker framework and TMRoPE positional encoding, provides solutions to the complex challenges of multimodal integration. Its streaming capabilities enable more natural and responsive interactions, while its performance across diverse benchmarks demonstrates its versatility and power.
As AI continues to evolve, models like Qwen2.5-Omni point toward a future where artificial intelligence can perceive and respond to the world in increasingly human-like ways, understanding not just the content but also the context of human communication across multiple sensory channels.




